
最近,国外一家 AI 初创公司 Mechanize 的三位创始人联合撰文,提出一个大胆的判断:RL 或许要迎来属于它的 “GPT-3 时刻”,但还需要拥有相当于数千至上万年“模型处理任务所用时间”的训练。
在他们看来,当前的 RL 模型还存在明显短板,比如泛化能力差、难以适应新任务等,这种局面其实很像 GPT-3 出现之前的语言模型——能解决特定问题,但难以迁移和扩展。
为了解决这个问题,他们提出了一种新的训练范式,叫作“复制训练”(Replication Training):让模型在虚拟环境中模拟真实软件的操作过程,比如使用浏览器、编写代码、处理命令行任务等等。
这种训练方式的好处在于任务目标清晰、评分机制明确,同时还能大规模自动生成训练数据,非常适合用在 RL 模型的系统性训练中。当然,它也不是万能的,比如在任务开放性和测试设计方面还有一些挑战。
但他们认为,复制训练是一条能推动 RL 模型走向通用智能的重要路径,有望带来一次类似 GPT-3 那样的能力跃迁。
综上,雷峰网(公众号:雷峰网) AI 科技评论对原文做了不改原意的整理与呈现:
当 RL 遇上 GPT-3 式规模化
GPT-3 向我们展示了一个关键事实:仅靠规模的提升,就能催生出强大、任务无关的 few-shot 能力,甚至在不少任务上超越了精心微调的模型。在此之前,想要在特定任务上取得最优表现,通常需要先用大规模通用语料进行预训练,再针对目标任务进行微调。
今天的强化学习(RL)则还停留在 GPT-3 出现前的阶段:我们依旧先预训练一个大型模型,然后在某些高度特化的环境中进行繁琐的任务级微调。但这一策略存在根本缺陷——泛化能力极弱。一旦模型面临的环境略有变化,性能便迅速崩溃。
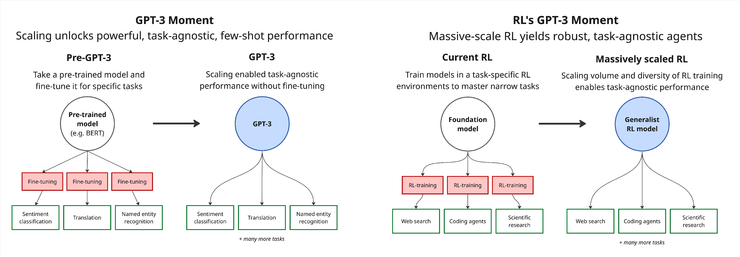
我们认为,RL 也将迎来属于它的 “GPT-3 时刻”。这意味着,训练方式将从在少数环境中微调,转向在成千上万种多样化环境中进行大规模训练,以培育出真正具备 few-shot 能力与任务无关泛化能力的智能体,能够灵活应对全新任务。
但要实现这一跃迁,前提是我们必须构建出规模和多样性远超当前水平的训练环境——这是推动 RL 走向能力爆发的关键。
要实现 GPT-3 级别的 RL 训练,需要多大的规模?
不过,目前的 RL 数据集规模仍然相当有限。
以 DeepSeek-R1 为例,其训练数据大约包含 60 万道数学题。假设每道题人类平均需要 5 分钟完成,总体相当于约 6 年的持续人工劳动。而相比之下,GPT-3 所使用的 3000 亿个 token 语料,若按人类正常写作速度来计算,则需要几十万年才能写完,数量级远不在一个水平。
另一方面,如果想让 RL 的算力投入达到当前最前沿预训练模型的水平,可能需要大约 1 万年的人类任务时间(即模型处理所需的时间,换算成人类完成同样任务所需的时间)。DeepSeek-R1 在 RL 阶段使用了大约 6E23 FLOP,对应约 6 年的模型处理任务时间。如果后续训练保持与 DeepSeek-R1 相近的训练周期与分组规模,那么将训练规模提升到 6E26 FLOP 级别,大致对应约 6000 年的模型处理任务的时间。
当然,随着任务多样性的提高,未来 RL 是否会采用更大或更小的批次规模,或增加训练轮数,目前仍无法确定。由于缺乏相关经验数据,要精确评估所需的模型任务时间仍有一定难度,但 “1 万年” 可能是一个合理的估算级别。
为了便于理解,我们可以将这一训练规模与某些大型软件工程项目进行类比:无论是 Windows Server 2008、GTA V,还是 Red Hat Linux 7.1,它们都被估算耗费了约 1 万年的人类劳动。
值得一提的是,将 RL 训练扩展到这一规模,从经济角度来看是可行的。由于算力支出在整体训练成本中占据主导,将 RL 的训练预算提升至与语言模型预训练相当的水平,有望显著提升模型性能,而不会带来成倍增长的总成本。
而真正的挑战在于:如何构建足够多样且可自动评估的 RL 环境。实现这一点,或许需要我们彻底重新思考 RL 环境的设计与构建方式。
复制训练或是解法?
想象一下,如果每次训练一个语言模型进行下一个词的预测(next-token prediction),都必须手动编写整套训练语料库,那几乎是不可能完成的任务。实际上,我们之所以能够训练出强大的语言模型,正是因为可以直接利用大量现有内容资源 —— 比如书籍、学术论文、博客文章,以及 Reddit 上的讨论等,构建出大规模、高质量的训练数据。
类似地,我们认为,强化学习也有望迎来自己的 GPT-3 时刻,而实现这一点的关键,很可能是一种被我们称为“复制训练”(Replication Training)的新范式。
其核心思想是:让 AI 模型去复现已有的软件产品,或其中的某些具体功能。
起步阶段可以从一些相对简单的命令行工具入手,比如实现某种哈希或加密算法的小程序——这些目标清晰、结构紧凑,适合训练初期使用。随着模型能力的提升,复制训练的任务范围也可以扩展到更复杂的系统,比如网页应用、专业软件,甚至是大型游戏。雷峰网
每一个复制训练任务,都会提供详尽的功能规范和一个参考实现。AI 模型的任务,就是生成一个行为上与参考实现完全一致的版本。这种方式的最大优势在于评估非常直接且客观:模型的输出要么与参考结果完全一致,要么就不一致。清晰的评分标准大大简化了训练过程中的评估机制,也提升了训练效率。
尽管“复制训练”任务在形式上可能与日常软件开发有所不同,但它们瞄准的,正是当前 AI 系统在工程能力上仍显薄弱的一些关键环节。比如,要让模型复现一个复杂算法(如一个包含上万行代码的加解密命令行工具,并要求严格遵循详细规范),就必须具备以下核心能力:
准确阅读并深入理解复杂的技术文档;
严格按照规范执行指令,避免逻辑或实现上的任何偏差;
能够识别并修复早期出现的错误,具备可靠的问题恢复能力;
在长时间、高复杂度任务中保持稳定输出,就像人类工程师连续开发数周一样,成果质量直接由正确性衡量;
面对困难具备足够韧性,不轻易满足于“差不多就行”的半成品。
这些能力的组合,是构建可靠、高质量 AI 工程系统的基础。而“复制训练”的独特价值就在于:通过高强度还原现实复杂系统,为模型提供了系统性磨炼上述能力的路径。这不仅补足了当前 AI 系统的能力短板,也为通用型智能体的训练奠定了关键技术基石。
我们预测,“复制训练”将成为 AI 训练的下一个核心范式。
这一判断源于当前 AI 发展的基本趋势:通过大量已有的人类创作数据,自动构建出丰富的新任务。就像自然语言资源广泛存在于互联网上一样,软件本身也是一种高度结构化且数量庞大的现成素材。复制训练正是基于这一前提,提供了一种可扩展、自动化的方式,能够高效生成复杂任务,推动我们向具备端到端开发能力的 AI 迈进——即那些能够独立完成整个软件项目的智能体。
当然,这一方法也并非没有挑战。比如,如何编写既高效又覆盖全面的测试,仍是一项不小的工程难题,往往需要大量人工投入。此外,从形式上看,复制训练也略显“人工”——在日常软件开发中,完全照搬已有软件的情况并不常见,尽管它在软件移植、遗留系统重构、“洁净室”重写等场景中确实存在。
尽管如此,我们仍认为复制训练提供了一条清晰且具可行性的路径,能够将 RL 训练环境扩展到支持泛化能力所需的海量规模。这种范式很可能成为 RL 实现“GPT-3 时刻”的关键——帮助模型积累成千上万年级别的任务经验,进而具备稳健、任务无关的泛化能力。
那么,复制训练是否就是实现“全自动劳动”的终极路径?我们并不这么认为。虽然它有望催生出能够依据详细设计说明独立完成复杂软件项目的系统,但这类系统仍可能缺乏人类所具备的开放性、灵活性,以及在跨领域场景中进行抽象规划和高阶管理的能力。即便未来 AI 成为顶级程序员,它们也未必能胜任更广泛意义上的决策与协调任务。
不过,我们相信复制训练仍有可能成为通往下一个训练范式的关键“桥梁”——正如在复制训练之前,我们也需要经历预训练这一阶段一样。我们对这一新范式的潜力与前景,充满期待
雷峰网原创文章,未经授权禁止转载。详情见转载须知。
