
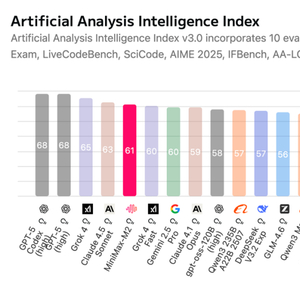
10月27日,来自中国的AI独角兽公司MiniMax稀宇极智正式发布并开源其新一代文本大模型——MiniMax-M2。这款仅有10B激活参数(总参230B)的轻量级模型,在保持优越性能的同时,实现了更低的延迟与成本,以及更高的吞吐效率,契合了新兴多智能体工作流对高效协同与快速响应的需求。
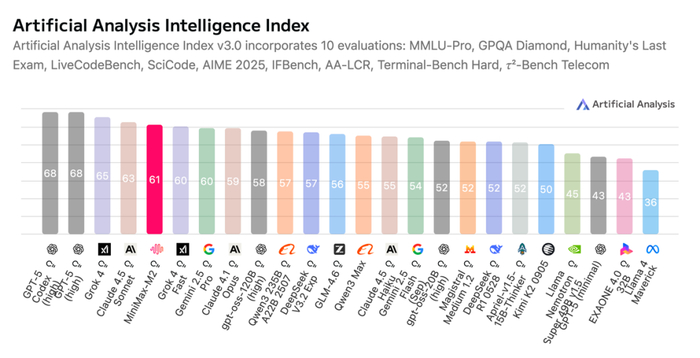
在行业测评榜单Artificial Analysis (AA)上,M2模型凭借良好表现,总分冲入全球前五、开源第一;超越了谷歌(Google)的Gemini 2.5 Pro和Anthropic的Claude 4.1等模型。其良好的性价比——综合成本不到Claude 4.5 Sonnet的百分之八 ,正试图从根本上改写这场昂贵的“算力游戏”规则。
MiniMax-M2的发布,在核心算法创新和商业化落地的“性价比”上的一次全新“超越”,为全球AI发展提供了一套具有竞争力的“中国方案” 。
海外热议——M2延续中国人工智能实验室在开源领域的领先地位
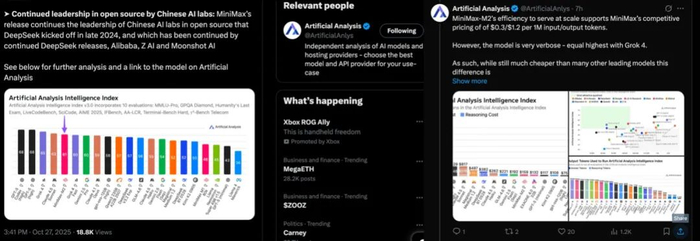
优异的智能水平、响应延迟与成本效率体验,让海外的科技大V和AI权威人士给予中国开源模型好评。头部开源平台HuggingFace的联合创始人Thomas Wolf表示,“哇——这是目前在人工智能分析中排名第五的模型——现已开源”;知名平台LMarena第一时间发X,向社区开发者推荐M2模型测试;权威榜单Artificial Analysis也在自己的社媒账号评论道,“MiniMax-M2的发布延续了中国人工智能实验室在开源领域的领先地位,DeepSeek于2024年底启动了这一进程,而DeepSeek的后续发布、阿里巴巴、Z AI和Moonshot AI也延续了这一领先地位”;甚至社交平台X也专门进行了News推送。
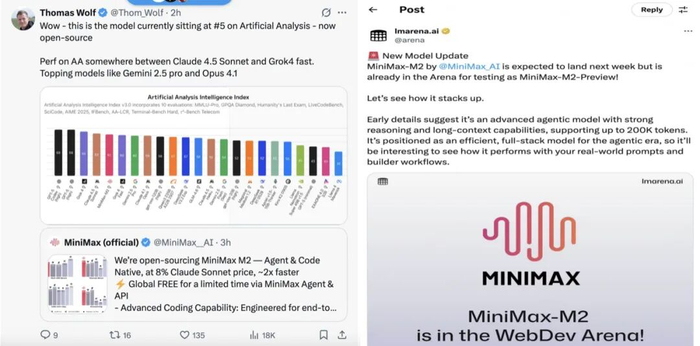

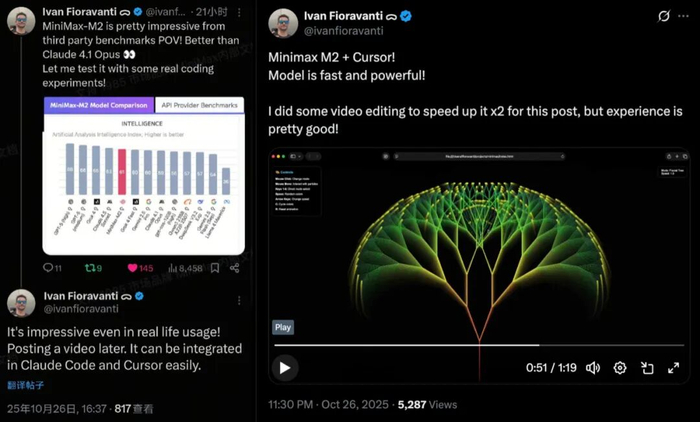
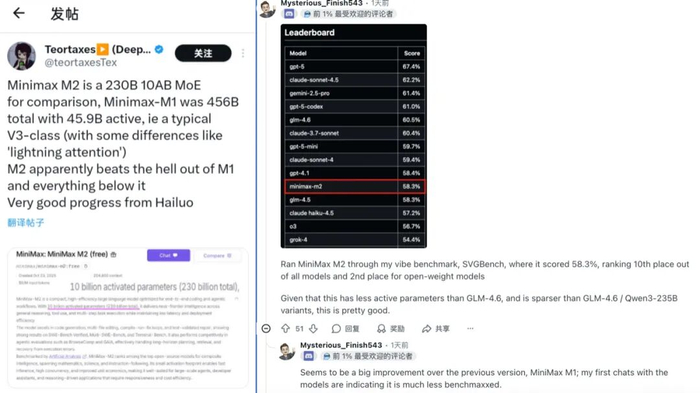
不少海外个人开发者接入API进行了不同维度的性能测试,并在技术社区分享真实案例CoreViewHQ 联合创始人兼CTO Ivan Fioravant迫不及待使用M2 模型和 Cursor编辑器 ,测试了分形结构树形图案等编程动画,呈现出一种几何递归的美感,他评价说,“MiniMax-M2 的表现很出色!甚至比Claude 4.1 Opus 还要好,即使在实际使用中也令人印象深刻”;Reddit社区技术大V在基准测试中运行了MiniMax M2,“它获得了58.3%的分数,这算是相当不错的表现”;
性能“亮剑”——跻身全球第一梯队
长期以来,全球大模型的“S级”梯队几乎被硅谷巨头们占据。而MiniMax-M2的出现,首次为这一梯队注入了强劲的中国开源力量 。
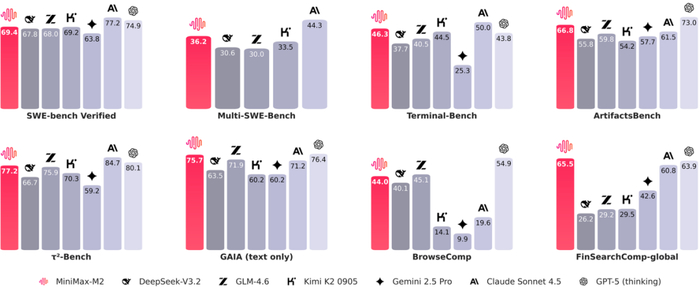
Artificial Analysis (AA)榜单以其评测体系的全面性著称,覆盖了模型在数学、科学与编码等多个核心领域的能力 。M2在此榜单上取得全球前五、国内第一的成绩是实力使然。
细究其分项能力,M2在被视为大模型“杀手级应用”的智能体(Agent)和编码领域,展现了实力:
优异代码能力:专为端到端开发工作流打造,在Claude Code、Cursor、Cline、Kilo Code、Droid 等多种应用中表现突出
强大Agentic表现:出色规划并稳定执行复杂长链条工具调用任务,协同调用Shell、Browser、Python代码执行器和各种MCP工具
优势性价比&速度:通过高效的激活参数设计,实现智能、速度与成本的最佳平衡
MiniMax-M2在设计之初就专为编码和智能体任务进行了深度优化。在实际应用中,它具备强大的端到端开发能力,能够处理多代码文件,执行“编码-运行-调试”的完整循环,甚至通过测试验证来自动修复代码。
在其他关键基准测试中,M2同样表现出色。例如,在Xbench-DeepSearch基准上,M2的深度搜索能力位列全球前二,仅次于GPT-5 ;而在字节新推出的金融搜索基准FinSearchComp-global上,M2同样位列全球前二,仅次于Grok-4。
这一系列成绩单清晰地表明,M2的智能水平已“站稳”全球第一梯队 ,具备了与硅谷顶尖模型正面抗衡的底气。
成本“破壁”——AI成本控制领域的中国方案
如果说M2的性能是对标硅谷,那么它的价格则可能是“掀桌子”。
在把控智能标准的同时,M2在价格上也展现了充足自信。一直以来,GPT-5、Grok4、Claude 4.5 Sonnet等模型,百万Token价格分布在10到15美元区间。而M2在智能水平齐头并进的同时的情况下,将价格压缩到了1美元以下:其API服务价格定在每百万Token输入0.3美金/2.1元人民币,以及输出1.2美金/8.4元,综合成本不到GPT-5的12%,并且不到Claude 4.5 Sonnet的8%。这被视为对业界尖端昂贵模型的一次直接挑战。
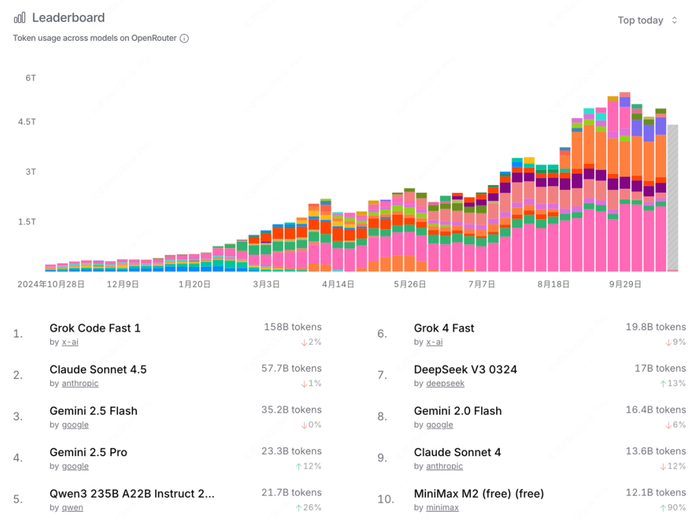
OpenRouter作为全球具有影响力的AI模型聚合与调用平台之一,其数据源于真实开发者的使用行为,极具代表性和权威性。M2在其平台上线不到两天,模型调用量已跻身全球前10。
算法自信——从“中国制造”到“中国创造”的创新引擎
MiniMax-M2的发布,除了模型本身,还折射出中国AI在全球科技版图中的“角色变迁”。
2025年10月,Meta发布了最新的强化学习(RL)论文《The Art of Scaling Reinforcement Learning Compute for LLMs》。这篇论文首次大规模、系统性地验证了来自中国公司MiniMax的原创算法。
Meta在超过40万GPU小时的大规模实验中,正式采用了MiniMax在2025年6月原发技术报告中的CISPO损失函数和FP32Head技术,并将它们整合进了Meta的ScaleRL核心配方中。实验结果显示,MiniMax的CISPO算法在效率上显著高于现有的DAPO算法,而FP32Head技术更被Meta称为其“消融实验中最重要的决策之一”。论文明确将MiniMax列为推动大规模强化学习ScaleRL突破的关键,并认为CISPO算法是适合大规模训练的首选方案。
从Meta对MiniMax底层算法的深耕,到今天MiniMax-M2模型以优异性能和突破性成本开源发布,不难看到了一条清晰的轨迹:中国AI正在完成从“中国制造”(应用模仿)到“中国创造”(算法原创)的战略转变。M2在全球的开源,正是一种“算法自信”的体现。MiniMax希望通过开源和强大的Agent能力,吸引海外开发者和技术社区进行二次开发和应用创新。

技术实力是参与国际竞争和规则制定的基础。过去,全球AI的议程设置、标准制定和伦理规范,基本由西方主导。而今,从年初DeepseekR1横空出世,再到Qwen3、GLM4.6等中国开源大模型不断刷新成绩,在国际舞台展露实力;多模态领域以Hailuo02击败Google Veo3模型,在海外社交平台掀起全球的“小猫跳水”和“动物奥林匹克”等潮流;如今中国拥有了与世界顶尖水平相当、并在部分领域实现超越的大模型技术,这意味着在全球AI治理的“牌桌”上,中国获得了更重的“话语权”。
强大的基础大模型是推动AI与实体经济深度融合的关键。MiniMax-M2的出现,更像是一份“中国方案”,用性能比肩顶尖水平、成本实现普惠、算法勇于原创的独特AI发展路径,向世界提交“答卷”。中国大模型在国际舞台的未来表现,以及它将如何在全球开发者的手中“开花结果”,值得我们持续关注。
发布
编辑:朱嘉琪
校对:张燕萍
审核:苏芳